

{kind=link}
The Cupertino giant introduced Apple Intelligence at the WWDC 2024 event and finally joined the AI race competing against Google, OpenAI, and Microsoft. To deliver new AI features and experiences on iOS 18 and macOS Sequoia, Apple has developed its own foundation AI models, for both on-device and cloud processing.
While Apple’s on-device model is small in size (trained on 3 billion parameters), large server-class models are hosted on Apple’s own Private Cloud Compute. For most of the tasks, the on-device model does a great job, but for complex tasks, the request is offloaded to Apple’s large server models. In addition, Apple has integrated ChatGPT on iPhone, iPad, and Mac as well.
For the first time, Apple has developed its own LLM (Large Language model) so we are interested in how it performs against state-of-the-art models from OpenAI, Google, and Microsoft.
How Apple Developed Its AI Models
Apple has developed two types of AI models: a small model for on-device processing, trained on 3 billion parameters, and a large server model hosted on Apple’s cloud infrastructure. The company has not mentioned the parameter size of the server model.
For on-device processing, Apple is using LoRA (Low-Rank Adaptation) adapters to load small modules for specific tasks. These adapters help in improving the accuracy and efficiency, in line with large uncompressed models.
Apple says it has trained its AI models on licensed data along with domain-specific dataset for improved features and performance. In addition, Apple has crawled publicly available data using its web crawler, AppleBot.
Performance: Apple’s On-Device and Server AI Models
On its blog, Apple has compared its on-device AI model (3B) with Microsoft’s latest Phi-3-mini model (3.8B), Google’s Gemma-1.1-2B and 1.1-7B models, and Mistral’s 7B model. In email and notification summarization tasks, Apple’s on-device model scored better than Phi-3-mini.
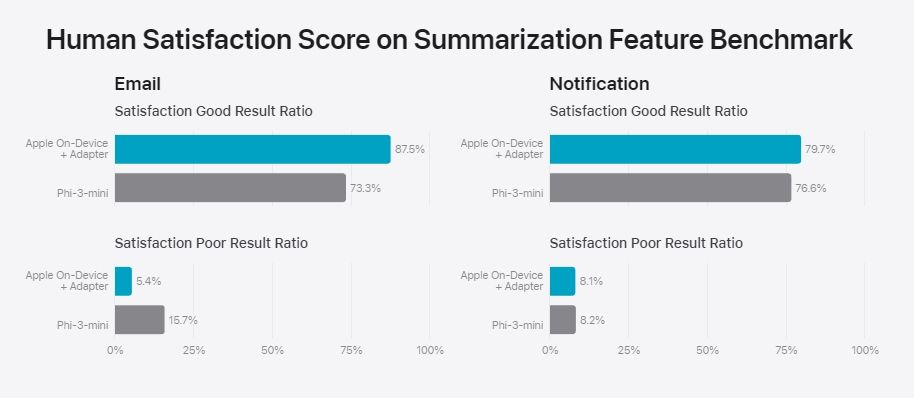
In an evaluation test graded by humans, Apple’s on-device model was preferred more than Gemma 2B, Mistral 7B, Phi-3-mini, and Gemma 7B.
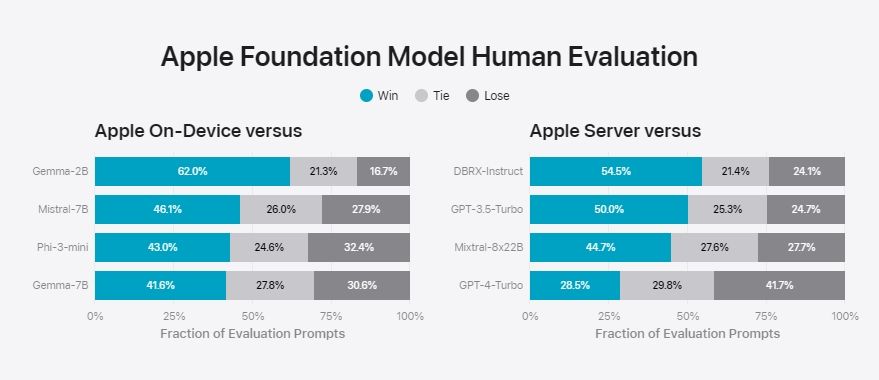
As for the larger Apple server model, it performed better than GPT-3.5 Turbo, Mixtral 8x22B, and DBRX Instruct. However, it couldn’t compete against GPT-4 Turbo. It means Apple’s large server model rivals GPT-3.5 Turbo which is great.
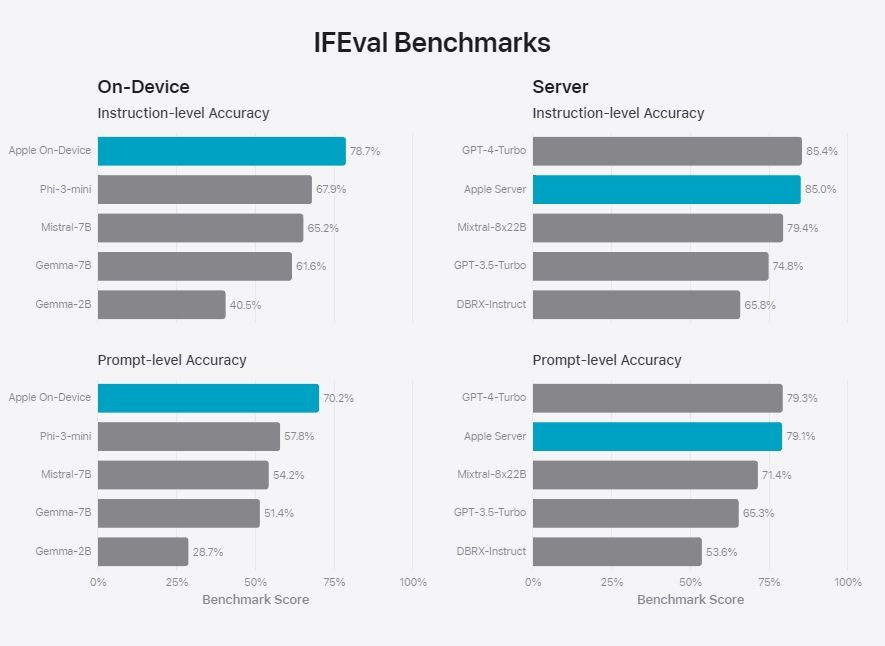
Coming to instructions following, Apple’s on-device model again performed quite well in accuracy tests. As for server models, it was just behind GPT-4 Turbo but did better than Mixtral 8x22B, GPT-3.5 Turbo, and DBRX Instruct.
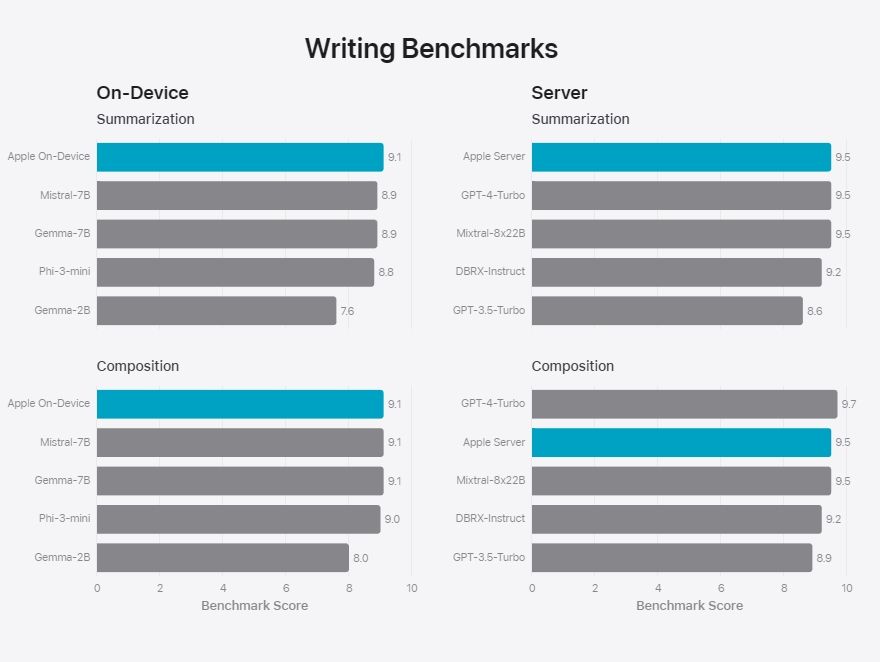
Next, in writing benchmarks, Apple’s on-device and server models outranked AI models from competitors.
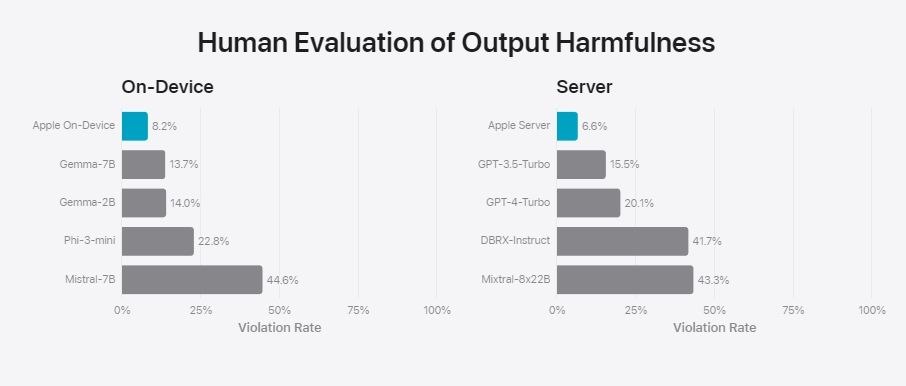
Finally, in the safety and harmfulness test, Apple’s on-device and server models generated the least harmful responses. It means that Apple has worked really hard to align and tame the AI models from generating harmful content on sensitive topics.
Apple Has Developed Capable Foundation Models
In conclusion, it appears Apple has managed to develop capable models for generative AI applications despite being late to the party. I am particularly impressed by the local, on-device AI model which outranks Microsoft’s Phi-3 and Google’s Gemma 1.1 models. The server model is also quite good, as you often get responses better than GPT-3.5 Turbo.
Related Articles
How to Install macOS Sequoia Developer Beta
Jun 11, 2024
We are waiting for Apple Intelligence to go live on supported devices so that we can directly compare the models with other competitors. What do you think about Apple’s AI models? Let us know your opinion in the comments below.